결정트리는 분류와 회귀 모두 가능한 지도 학습 모델 중 하나이다.
결정 트리는 마치 스무고개를 하듯이 예/아니요 질문을 이어가면서 학습합니다.

이렇게 특정 기준에 따라 데이터를 구분하는 모델을 결정 트리 모델이라 한다.
한번의 분기 때마다 변수 영역을 두 개로 구분한다.
질문이 너무 많아 지면,
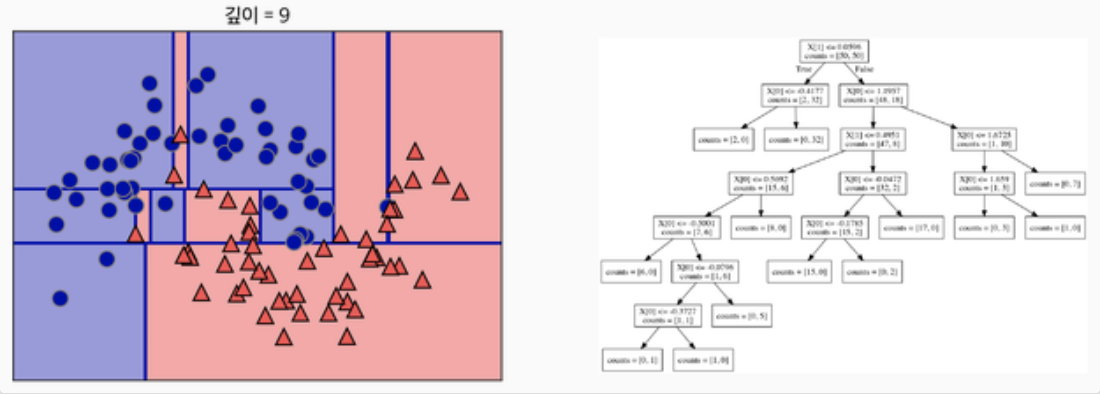
오버피팅이 될 수 있습니다.
가지치기 ( Pruning )
오버피팅을 막기 위한 전략으로 가지치기라는 기법이 있다.
즉, 최대 깊이나 터미널 노드의 최대 개수, 한 노드가 분할하기 위한 최소 데이터 수를 제한하는 것이다.
엔트로피( Entropy ), 불순도 ( Impurity )
불순도란, 해당 범주 안에 서로 다른 데이터가 얼마나 섞여 있는지를 뜻한다.
결정 트리는 불순도를 최소화하는 방향으로 학습을 진행한다.
엔트로피는 이 불순도를 수치적으로 나타낸 척도이다.
엔트로피가 높으면, 불순도가 높다는 뜻이다. ( 1일 때 최대이다. )
1이라는 말은 정확히 서로 다른 데이터가 반반이라는 뜻이다.

정보 획득 ( Information gain )
분기 이전의 엔트로피에서 분기 이후의 엔트로피를 뺀 수치를 정보 획득이라고 한다.
공식 : Information gain = entropy(parent) - [weighted average] entropy(children)
parent -> 분기 이전 엔트로피, children -> 분기 이후 엔트로피
[weighted average]entropy(children) -> children의 가중 평균을 의미한다.
가중 평균을 하는 이유는 분기를 하면 범주가 2개 이상으로 쪼개지기 때문이다.
*회귀
주어진 데이터가 어떤 함수로부터 생성됐는지를 알아보는 함수 관계를 추측하는 것.
가설(방정식이) 몇차 방정식인지, 계수는 각각 무엇인지 알아볼 때, 계수가 선형이면 선형 회귀 분석, 변수가 여러 개면
다중 선형 회귀 분석이라고 한다.
* 오버피팅 ( Overfitting 과적합 )
모델의 파라미터들을 학습 데이터에 너무 가깝게 맞췄을 때, 발생하는 현상이다.
너무 세밀하게 학습 데이터 하나하나를 다 설명하려고 하다보니 정작 중요한 패턴을 설명할 수 없게 되는 현상
머신러닝 - 4. 결정 트리(Decision Tree)
결정 트리(Decision Tree, 의사결정트리, 의사결정나무라고도 함)는 분류(Classification)와 회귀(Regression) 모두 가능한 지도 학습 모델 중 하나입니다. 결정 트리는 스무고개 하듯이 예/아니오 질문을
bkshin.tistory.com
'CS > DataMining' 카테고리의 다른 글
| Fisher's Linear Discriminant Analysis (0) | 2021.04.21 |
|---|
